

If you’re a data/analytics engineer like me who grew up on dbt, dbt-utils is the quiet heroes of your working days. It’s just jinja string manipulation and substitution at the end of the day, and you still have to cast column data types for parameters, and there isn’t good error handling. They don’t make you feel like a genius, and they’re not something you brag about to your teammates. But back in 2020 they showed up to help, and this was a breath of fresh air. It’s like someone walked the same paths I did. They wrote some pro tips on the bathroom stall door while I was sitting on the toilet in a moment of reflective doubt, and then spoke to me (metaphorically).
Here you go my guy, this macro will save you some time. You don’t need to write all that boilerplate SQL yourself.

And I got to move on with my day. I believe a lot of you feel the same way too.
Going faster is sometimes about how you feel
A person's experience of time passages in daily life does not fluctuate with age, but with their emotional state. Put simply – if you are happier, time passes faster. If you are sad, time drags. - Source
I think about how my time is spent very deeply in my workflow. Yeah, I could ask my friendly neighborhood chatbot to spit out some auto-generated SQL. But you know like I know, LLM’s lack of determinism forces you into constant review mode. Especially when I’m juggling debugging context AND emotionally charged DMs from frustrated end users, it doesn’t actually solve the core problem I care about - mental load. That odd feeling that I’m reinventing the wheel someone has already battle-tested. I wish I could reach through a portal to copy and paste that code and just use the same thing in my time of need. That’s what quick utilities like dbt-utils gave me while developing, before, during, and after my time at dbt Labs. It’s because my incentive isn’t to show off how clever my SQL is. My incentive is to move as fast as possible because my actual bottlenecks are taking an abstract business request and massaging my data like tetris. And then it’s just waiting for my data pipelines to run. But today, working with data feels like debugging sludge sometimes…most of the time.
I was at Tobiko - learning, using, and teaching SQLMesh, and realized that I missed that same feeling. Like, where’s my “Here you go my guy…” moment?! So I frantically scrounged around the docs and saw there was a handful of the ones I care about from certified good guy Alex Butler:

And I just presumed without reading further that he must have ported all of dbt-utils into SQLMesh. So when I tried it out myself, I was struck with a curiously frustrated eyebrow raise when it didn’t work.
“Here you go homie…oops nvm, can’t help you there.”
Getting my hands dirty
I’ve come to a place in my career where I’m not waiting for the world to change to meet my needs. I’m grown up enough to make my workflow what I need it to be. And so I reflected at work and in my shower (lots of great ideas in my mind palace during a shower). And most importantly, I asked real people who care about utilities like I care about them. I talked with the Tobiko team internally, with Alex Butler who contributed other util macros in the past, and with my good ole’ buddy Randy (we worked at dbt Labs together).

And with Alex Butler:
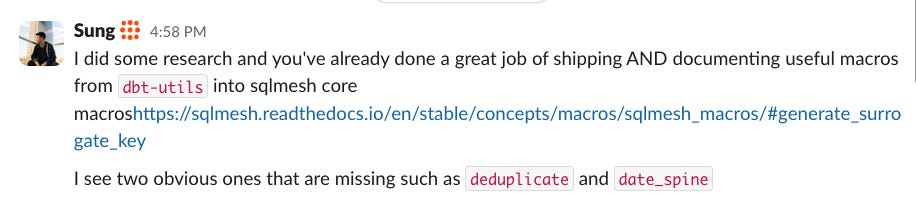

So with some validation from people I respect, I started small with my personal favorites.
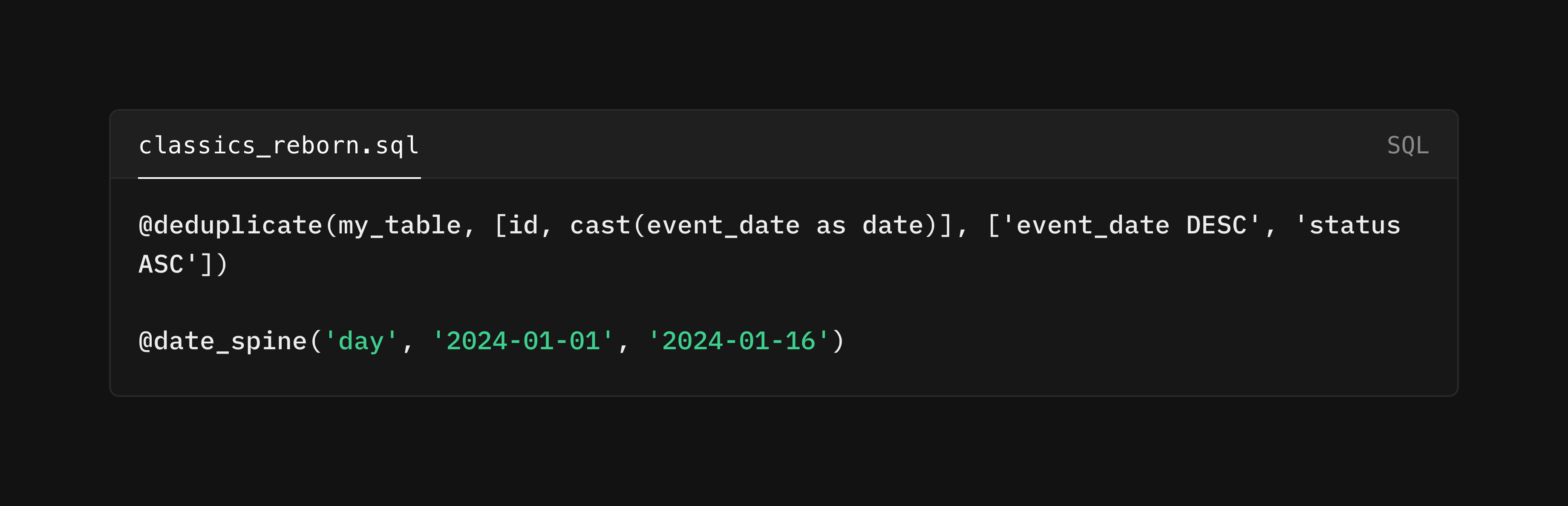
The Blueprint

What’s really nice about my starting point is that I stand on the shoulder of giants. There was already a blueprint in place for me to start from. Literally starting at line 889. Generate surrogate key was/is one of my favorite macros because when dealing with messy data, you don’t always get a data dump from source systems that have a guaranteed primary key. You usually get a csv dump or API request payload and the system is just like, “Good luck”. I kid you not, I did consulting for a healthcare startup that was sent a SFTP dump of their data in a gzip with an excel spreadsheet attached with the data model, and primary keys didn’t match up..ha! So yeah, there’s real world applications for this in the before times and the now times. Anyways, back to the main show.
I can just build a single function and anytime a user adds the macro to their model, it will render the SQL exactly as I expected. You know what’s cool about the obvious? It’s when it’s explicitly written as a docstring == unit test (I didn’t know this was possible and I love it so much). I didn’t even have to context switch to the literal docs to figure out how this works. And all of this with proper types 🧃.
So TLDR:
Copy and paste this as a starting point for my new SQLMesh macros
Write a docstring unit test that shows my inputs and expected outputs
Write out the logic in python using SQLGlot to take advantage of working with SQL as an AST so that it properly renders the SQL on any query engine
Return a SQLGlot expression that will render as SQL when used within a SQLMesh model (SQL file)
My Hands are Dirty
With a rush of adrenaline, I went straight into building out the date spine macro. I felt this odd sensation of a side quest, like…I don’t know how this is going to play out. I’ll probably stumble and fumble and feel dumb, but I’ll emerge out the other side better for it. But first, I had to learn how the heck SQLGlot works because I’m using python and ASTs as a mental model to write SQL, which is not something I’ve done. Keep in mind my reference point is jinja macros similar to the rest of you. You can see how my thinking evolved in real time in this PR. Before you examine the macro below, you should see how I went down a very bad path of hand-rolling individual implementations of the date spine for each query engine. I was using SQLGlot to write SQL, but I was NOT using SQLGlot as intended (sucks to suck).
Thankfully, I asked my teammates before I finalized this approach because this would have been a maintenance nightmare. The whole point of writing SQLMesh macros with SQLGlot is to get transpilation out of the box, and I was literally working against that design pattern. So I took time to mourn, sulk, pound sand, then built what you see before you now. Something much simpler to understand AND maintain 🧃.


It was all worth it
The only measure of success was to make someone feel how I feel: data work sucks a little less. And I got what I wanted twice over.
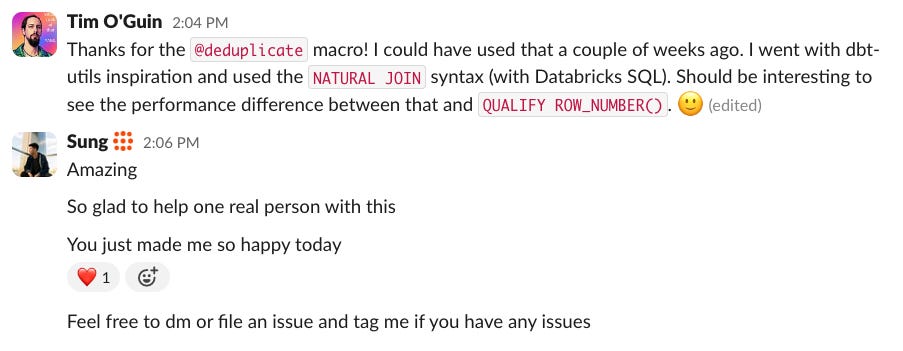

Ultimately, this is what open source is all about! Connecting with real people with real problems and solving those problems. And it feels deeply satisfying that I reinvented a wheel just once so data engineers don’t have to go through what I did 1000 times over to come to the same conclusion. I made these macros to be easy to reach for and congruent with how you already think in your SQL workflow. I hope that’s true for more than 2 of you ;)
What Now?
I missed how dbt-utils made me feel: make data engineering suck less. And I think you miss it too if you’re using SQLMesh, and that doesn’t have to be true anymore.
I’m excited for our craft to make it more normal to build ergonomic data utilities for ourselves. Everything we touch doesn’t have to be the next great framework. There’s tons of low hanging fruit ripe for the harvest, and I know we’re all capable.
I can’t wait to see what you build for all of us :)
