
Flow State Data Engineering: I want it to be normal
Or: what it takes to get to Flow State as Normal

Disclaimer: I work at dbt Labs, but the opinions here are my own.
Intro
I was in the middle of writing my frictional frustrations with data workflows and came across these posts:
I’m glad I’m not alone. Thank you both for encouraging me to write more than a diary entry. Below is my inner dialogue about data development ergonomics, and what I want it to look like in the future (sooner rather than later) :)
My Workflow Today
I’m an analytics engineer and wake up to start my day. I check slack. Slap a 🧃 reaction here and there on threads I like. Next I’m tasked with adding and updating a dbt model: revenue_by_month.sql. I write a couple lines of code. Notice github copilot is making mediocre suggestions and ignore them. I open up another tab to see how my code is compiling side by side my dbt model file. I think to myself the below things.

Who else is touching this precious file of mine? I’m tired of pull request clashing
What’s historical performance on this and am I beating it?
How often does this fail in production?
Who uses this model and how often?
What dashboards will this help vs. hurt?
What’s a data preview based on my updates look like?
How many scheduled data pipelines are tied to this model?
How much does this cost to run in production and am I helping vs. hurting?
What are existing database permissions on this model?
Anyone working on pull requests in real time that rely on my work?
What’s a data diff compared to current production data?
I drown in my questions and browser tabs.
I give up:
select * from {{ ref(‘stg_revenue’) }} where flow_state=0 limit 5
I time traveled back to my old ways of working.
How Sung Opens His Demos: Demo - Watch Video
I thought data engineering was supposed to be more fun than this. Each of those questions is at least one tab and a couple clicks in my browser or IDE. Let’s count ‘em out Blue’s Clues™️ style.
Who else is touching this precious file of mine? I’m tired of pull request clashing → Github PR page → 2-3 clicks
What’s historical performance on this and am I beating it? → Query History → 2-3 clicks and typing out a filter
How often does this fail in production? Look at a tab in Airflow or dbt Cloud → 2-3 clicks and typing out a filter, scrolling and eyeballing
Who uses this model and how often? Query history for the specific table → 2-3 clicks and typing out a filter, scrolling and eyeballing
What dashboards will this help vs. hurt? → Dig into BI configs → 5-10 clicks and pray my intuition guides me to the right bar chart
What’s a data preview based on my updates look like? → Query Console tab → 2-3 clicks, copy and paste my compiled dbt SQL, scrolling and eyeballing
How many scheduled data pipelines are tied to this model? → Airflow or dbt Cloud or random scheduler and click 10-20 different times across DAGs
How much does this cost to run in production and am I helping vs. hurting? → go through a whole tutorial and babysit some SQL commands to copy and paste if I don’t want to model them in dbt
What are existing database permissions on this model? → similar as above
Anyone working on pull requests in real time that rely on my work? → Slack thread with 2-3 replies
What’s a data diff compared to current production data? → Query Console tab and run a query against production and/or learn a whole new tool
That’s 11 tabs and 40+ clicks more than I want in my life, and in practice I’ll touch maybe 2-3 of these during active development. These aren’t just nice to have questions. All of these are more than tedious introspection. Someone other than me will have these same valid questions, and I won’t have great answers because I didn’t have 11 tabs constantly open and updated at the time of asking.
But the real tragedy of this is that we all think this flow state fragmentation is normal and okay (even with the best of tools). It’s not.
Who doesn’t have these problems (or at least it’s less painful)?
I’ve been watching a lotta random youtube software engineer influencers and their “here’s my tech stack” videos and why they choose it. The most astonishing thing is what I didn’t hear, “Damn, I have too many tabs open and it’s so hard to do my job even with the best tools.” And even more dawning, the mechanics of these tools are commodified, but the UX isn’t. The main things these people talk about are speed and how it feels to get their jobs done. Things that feel so aspirational for my data workflow are normal small talk for software engineers today. Example below.
The biggest prize these people get: headspace to do the work they love…and brag about it on substack, youtube, reddit, etc.
Imagine the Future with Me
I’m an analytics engineer and wake up to start my day. I check slack. Slap a 🧃 reaction here and there on threads I like (some things never change). Next I’m tasked with adding and updating a dbt model: revenue_by_month.sql. I write a couple lines of code.
Here’s where it gets juicy: smooth where I want it and friction where I need it.
Who else is touching this precious file of mine? I see who exactly is touching it in a right side panel in real-time and historically similar to Spotify’s friend feed

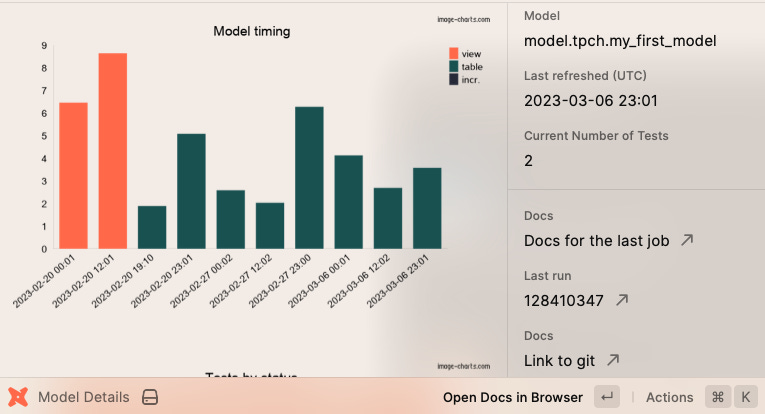
source: my spotify What’s historical performance on this and am I beating it? I get a dynamic mini map based on the file I’m working on

source: https://github.com/b-per/raycast-dbt-cloud-metadata How often does this fail in production? See answer to question 2
Who uses this model and how often? See answer to question 1
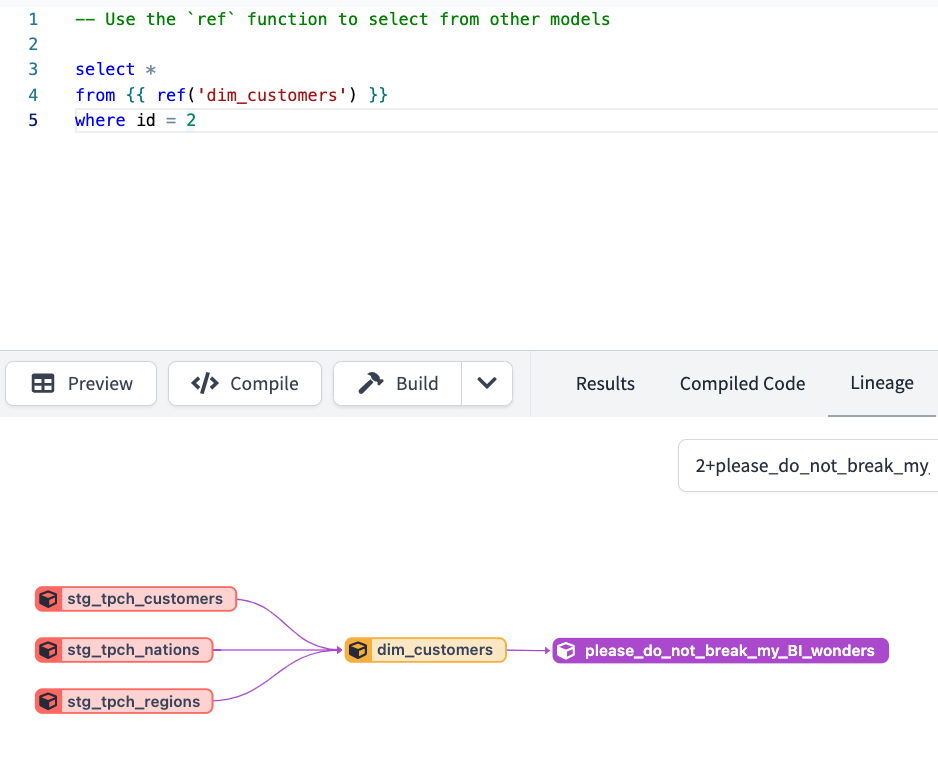
What dashboards will this help vs. hurt? Auto-impact lineage within my IDE and some nice green check marks or red x’s to help me course correct. AND hot-reloading of my BI dashboard along with a diff to production’s UI.

source: dbt Cloud IDE lineage What’s a data preview based on my updates look like? Automatic query runs as I’m typing and grays my preview pane if syntax is wrong
How many scheduled data pipelines are tied to this model? → Dynamic side panel that I’m breaking new ground with my net new dbt model

source: https://github.com/b-per/raycast-dbt-cloud-metadata How much does this cost to run in production and am I helping vs. hurting? Automatic billing stats before AND after my run. A mini calculator dynamically generates for me and provides historical costs to compare against.

source: https://cloud.google.com/products/calculator/#id=b82d7581-21f9-4903-b315-b499fa297a6e What are existing database permissions and usage on this model? → See usage analytics and permissions in a side panel like how notion does page analytics

source: my notion page Anyone working on pull requests in real time that rely on my work? → See answer to question 1
What’s a data diff compared to current production data? → Get a tool like data-diff to automatically run as I type in real time
data-diff --dbt setup and demo - Watch Video



Let’s sprinkle in green, red, and yellow checkmarks for all the above in directional correctness!
Now I think to myself. I traded tabs and clicks for screen bloat like how websites did too much back in the early 2000s (example below). It’s a messy mix of IDE UI components, quick notifications, dynamic terminal outputs, etc. And I actually don’t know if the above is the ideal future state. All I know is that I see fragmented components that answer these questions super well in pockets, but the outcome remains the same:
No flow state
 | Show video, Surfing ...")
I’m less interested in specific UI components and pixel curation and far more interested in speed and how it feels to ship data every single day. I want these questions to be as easy as hovering over my keyboard. I want my floor to be lifted high. I’m tired of scavenging for these experiences. I want them embedded in my flow state. I want to feel like the person below, who’s just so in their groove.
Super Saiyan Flow State - Watch Video

What’s Next Silly Boi?
Snowflake and Databricks invested more in IDEs as a first class experience with their latest extensions. I wrote about how players like DuckDB are making millisecond SQL queries a normal thing.
The cultural momentum is on our side to make data flow state a first class experience!
Copying and pasting the SWE workflow to data engineers may not be the answer, but it’s hard to deny what they have. Headspace to do the work they love. And gosh darn, it’s worth trying to replicate if that’s the case!
So, you’ll probably see me this year building filthy MVPs (minimum viable products) to solve the above problems for dbt and beyond, one gosh darn tab at a time. Heck, I’m willing to roll up my sleeves and learn rust if I have to (to get speed apparently). The best way to predict the future is to build it together. That’s why I’m writing this. Now, here’s where I figure out why you’re reading this.
Do these problems resonate with you?
Do you care?
What are you doing to solve the too many tabs problem in your data workflows?
Want to build something together?