


Going Faster is the Greatest UX
And we as data engineers are starving for it


Civilization advances by extending the number of important operations which we can perform without thinking about them.
- Alfred North Whitehead (Not Sonic)
Column level lineage is a wonderful thing that has a low ceiling. Going faster made me realize solving a problem wasn’t about becoming a faster reader of encyclopedia-level lineage graphs. I needed better design. I needed the right level of context. If mechanical speed is the answer to the problem, it melts it away. When speed is not the answer, I can move faster to figure out the real answer without spending time speeding up a workflow that was always going to lead to a dead end (re: spaghetti lineage). Alright, now you got some framing, time for the rest of the show.
I saw this quote by Alfred as a thumbnail for an esoteric youtube video about object oriented programming. I didn’t click the video, but man oh man did that line just crystallize why flow state matters so much to me. That’s right baby. You didn’t think I’d stop talking about that since I wrote about it last year. Well surprise y’all! I’m talking about it again right here right now, and if you’re reading this you probably have too little of it. Either way, welcome to the show! Feel free to read my previous post as a primer :)

You may have heard this phrase in software engineering:
Make it work → Make it right → Make it fast
And trends in rust are making normal:
Make it work (fast by default) → Make it right (it’s already fast)
This is where data engineering is right now:
Make it work (90% stops here) → Make it right (if we’re lucky and haven’t drowned in the gravity well of ad hoc requests, and no…simple primary key tests aren’t enough)
I say this because these posts awakened a shower thought moment, the need for speed.


And I’ve seen so much more sentiment working on open source AND selling software: going faster is all we want. And I’m tempted to write a lot of shallow components to this, but it’s better served talking through column level lineage (CLL) as the main character here. Especially with the explosion of column level lineage becoming a commodity overnight (my hunch is everyone is using SQLGlot under the hood), it dawned on me feature-functionality isn’t enough. Tools have to make you actually go faster with their mechanisms, not just show you what’s possible with a pat on the back that says, “Good luck, kid”.
I’m pumped for this to be a shared dialogue. Well, I guess it already is :)
Who are the role models?
Alright, I need to set the tone for why this matters so much to me. It’s because I admire those that are already making things faster for other parts of my workflow. How these tools make me feel is how I want to make you feel. Thankfully, the mantra, “gotta go fast” isn’t anything new to the python ecosystem and in turn the data ecosystem. It’s such a delight to see this problem space take center stage via the halo effect of:
ruff: very fast python linter and formatter
pydantic: fast python runtime type validation
polars: faster dataframes than pandas
duckdb: fast analytics database for local development

At least one of the above tools is leveraged by a data tool you touch everyday:
It’s bringing consumer-grade expectations to how we do work (think: would you want to use an app that takes 10 seconds to load each time you click a button?). I think the human condition has been overwhelmed with how normal millisecond performance is in everyday life, that there’s more and more frustration with how slow things feel, especially in data. And yeah, we can use common sense to say, the reaction time of clicking a button has different performance implications than querying millions of rows. But…it doesn’t make the disappointment go away. These role models are important because they give the rest of us freedom to build a shared imagination. We collectively think to ourselves, “I want my work to be faster and less disappointing. These other teams are doing so. Why can’t I?”.
And you know what’s really nice? Software Engineers are already living out a story we want to, so we can learn from their battle scars.
Turborepo: monorepo workflows for javascript
Biome: Rome, previously mentioned in this post, has became Biome
Oxc: Similar to Biome: parser, linter, formatter, transpiler, minifier, etc
Turbopack: New bundler powering the Next.js Compiler (status)
I’m jealous and eager and frustrated and can’t help but make this tagline my whole personality, “It’s time for my data work to go faster…or at least suck less.” Going faster matters because it has always mattered to us in life and now there’s enough role models in software engineering to think, “It’s time for a new data engineering normal.”
Where do I even start?
I illustrated in my original flow state post how it’s achieved through glueing context for change management (think: what dashboards does this PR help vs. hurt?). As I’ve been focused on building and selling solutions to answer the question, “What’s the data diff between dev and prod?”, I have a deeper appreciation for how flow state is achieved through mechanical speed + ergonomics.
There’s a flood of areas that rush to mind during development, but the ones that scream loudest are:
How much context do I really need?
What should I do with this information?
How does it feel to iterate 10 times in a row?
How much context do I really need?
I’ve seen lineage graphs as sprawling as all the spaghetti I’ve ever eaten in my life. I’ve seen people work so hard to follow GitLab’s public dbt role model of a project just to find out they’ve hit the same dead ends with a giant lineage graph. The loading and clicking are so slow that they just don’t use it anymore. Heck, I’ve seen lots of data teams not use dbt docs/lineage in practice because even when it does work, can anyone really make sense of 1000 nodes on a graph? Do people really want to scavenge for the needle in the haystack each time you want to understand the blast radius of your pull request (much less 5 PRs in parallel)? The quiet part out loud that’s too socially expensive to say, “No”.
So in practice, people just eyeball for green and red checkmarks in their logs, comment LGTM, and merge to prod. I’ve seen hundreds of dbt projects do this, literally hundreds. But these people aren’t the problem, being thrown an encyclopedia’s worth of information for a docs website that doesn’t even load, is the problem. I’m not the only who thinks that: Dagster built a dbt docs prototype from scratch to solve this. AND even if all the mechanics are wicked fast, you still have to open tabs to verify how your data looks and feels at each step. You may do that once, but 20 times in a row? This is where you say, “Nah, dude.”

{kind=link}
What should I do with this information?
Even if I do find the lineage subset “needle in the haystack” through your favorite IDE or VSCode plugin, it doesn’t answer the actual question I want to, “How will my data pipeline look and feel if I change it in these 10 ways?”
Sure…if you have deep tribal knowledge and familiarity with this lineage subset, you contort a mental model to get a rough sketch of the blast radius. However, this has a low ceiling. You will only ever know the rule of thumb. You will only ever have a scratchpad of ad hoc joins in a query console with scraggly comments to validate changes. If you see 20 nodes in your subset, we got to be honest with ourselves. We’ll rationalize to ship sweeping changes to the data pipeline rather than grinding through each step in the graph. You know why I know this? Because I’ve done the same darn thing many times over in the past when I first learned dbt.
Developer familiarity is NOT the same as developer speed.
How does it feel to iterate 10 times in a row?
This gets to my core point. People don’t care about lineage diffing. They really care about data differences between dev and prod, and that means they need to data diff. I run data diffs on the daily whether through open source data-diff or Datafold Cloud. I’ve gotten the great pleasure and curse in noticing minute details most people on first impression don’t care about. These are the kinds of things you care about after you run them 10 (okay…1000) times in a row, and what I’ve learned working with hundreds of data/analytics engineers. I bring this up because understanding CLL impact starts with understanding how data changes first; you can’t flesh out a full mental model with nodes on a graph. No silver bullets, but there are great starting points.
When I make and run changes to my dim_orgs dbt model, my mental model feels good when:
data-diff --dbt
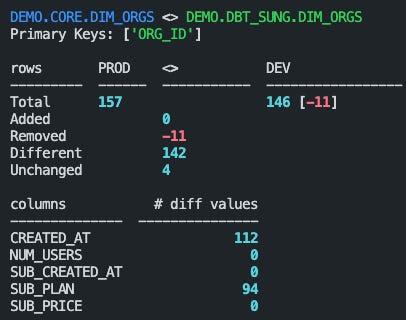
Someone else does the math for you
Validates what configs are used as inputs to this output (think: what primary key is this using?)
Formatting draws the eye from top to down without zagging your eyes too much
Color coding draws your eye to the subset of info you care about most
That builds you a reference point to keep running if your SQL changes will adjust a specific line item in this report
You can read everything without scrolling and clicking around the output
When blue-green deployment color-coding distinguishes prod on the left and dev on the right
All of this doesn’t need to be consciously recognized to be consciously rewarding
Because when the mechanical ergonomics are empathetic and fast, you don’t think about them. Your mental model doesn’t require that fluff. You’re just immersed in the work. You even get to gamify it where you run this 10 times in a row after each SQL change just to see how it feels. You get to feel like your role models:
ruff data-diff is so fast that sometimes I add a quick SQL limit clause just to confirm it’s diffing.
-Sung, author of this post
And when you run it for the 10th time after all the changes you made, this is when CLL impact matters to you.
data-diff --dbt --cloud

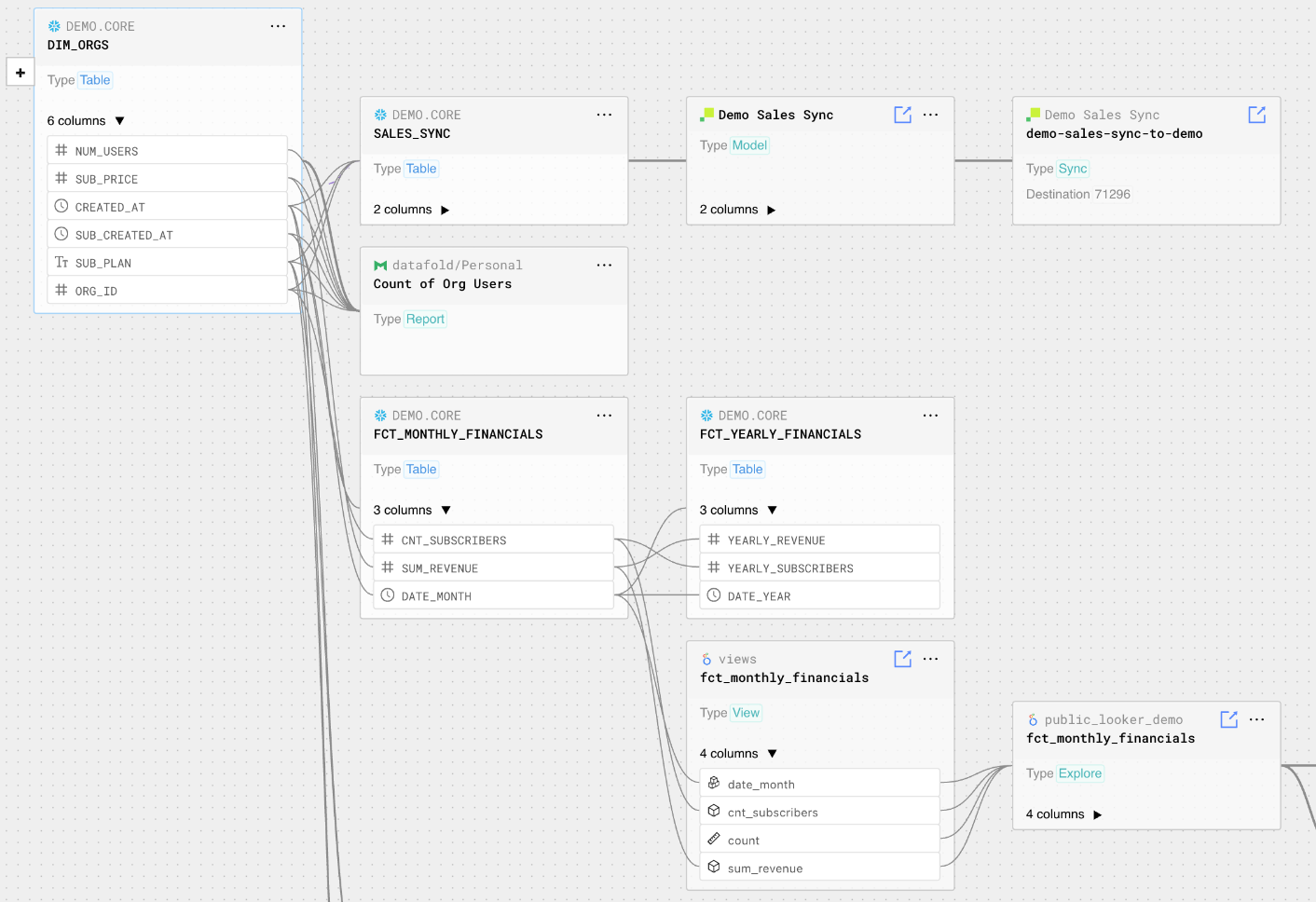
Because how data differences look and feel underly every other step to contextually glue column level lineage impact.
Who do we need to talk to about the blast radius of these changes? (think: changing revenue formulas that feed into Looker dashboards).
- YOU, once you have better CLL impact ergonomics
What now?
My only call to action:
Demand every molecule of your workflow to be faster, no compromises.
Because it’s always nice to go faster :)
Column Description Propagation in SQLMesh - Watch Video
