
Open Source has my Whole Heart
I want it to have yours too


I work at Tobiko Data now — creators of SQLGlot and SQLMesh. I’m joining them because open source is a beautiful pursuit. I’m joining because we’re solving problems I (we) love. I’m joining because I enjoy and respect these people and the feeling is mutual. I’m joining because I get a lot of natural excuses to hang out and literally work with you in public, my data people, and I wouldn’t have it any other way.
And yes, I’m joining a direct competitor to a place I loved working at: dbt Labs.
Is this evolution or a pivot or both? In my Feelings
Abridged Career Path
I’ve been in data my whole career. Like many of you in the early 2010s, I stumbled into it by chance in my first job doing accounting analytics. I was literally verifying if debits equaled credits using this proprietary SQL-like language called audit command language. And yes, it’s as awful as it sounds. The kind of awful where you can’t google anything and have to read the manual. I did “pull request” reviews through color coded email replies in lotus notes. If you can’t relate, I hope you never do. If you have trauma like me, I hope you’re a healed person. Also, the accounting busy season hours were not my cup of tea, so I did some soul searching to figure out that I loved the data and how solving problems with it made me feel. I didn’t like only doing it for accounting.
My next move was at Slalom where I bootstrapped my way to being a data engineer. I’m talking the whole 9 yards baby: airflow, terraform, python, SQL, dbt, google cloud, a little AWS. I got to consult across the nation from big tech to healthcare startups to traditional enterprises. I got to enjoy the whole buffet. I really loved this season, but tastes change. I wanted to digest a new reality. Consulting felt like I was building this beautiful garden for someone else, only to hand it off and imagine the fruits of my labor (credit: Winnie). If I wanted to evolve this, I had to build this beautiful garden and invite people into it, knowing my team will sustain it. So I did some soul searching and realized I want to build and sell product. And, I’ll taste every juicy🧃 strawberry and turnip I find in the dirt.
I got lucky. I found dbt Labs series B post back when they still called themselves Fishtown Analytics. I applied for the solutions architect job and got it! I threw myself ferociously into open source contributions. At first, it was for the prestige and seeing my little GitHub commit graph flooded with green, but thankfully my taste for dopamine evolved. I grew to love it because the problems I specifically solved juiced me up like no other. I was an addict. I still am. Because the wonderful thing about open source is not how good or bad your code is. It’s wonderful because it shows you care. It shows how you think. It shows how you struggle. It shows how you overcome. It shows how you agree and disagree well or poorly with maintainers and the community. It shows that who we’re doing this for and with are the ultimate prize.
I don’t remember any of the code I merged. All I remember are the treasured and intimate moments going back and forth and side by side with Jeremy and Kshitij and Alice and Michelle and Doug and Winnie and Randy and Anais and Matt and Afzal and Bela and Izzy and and Anders and Julia and Barr and Yamini and Benoit and Mike and Haldan and Jay and Ryan and Tristan and Nate(x2) and Travis and Gerda and Ric and Kira and Andrew and from the community: Max and Jonathan and Brandon and Brian and Mike and Alex and Julien and Josh and Mason and Kevin. And many more I can name off the top but I’ll stop flooding you. These people, including you, are the prize. And open source and selling software at dbt Labs was and is one grand excuse to get to know you.
Flat out: this has been my best job thus far. I loved every moment of it. I even told Tristan Handy (CEO of dbt Labs) face to face.
But things change.
I left dbt Labs because a lot of people I loved working with were either laid off or left or I couldn’t work with them in the same way anymore. I did some soul searching and I had to ask a haunting question.
“Am I good only because of the hype of dbt or am I good because I’m actually good at sales + open source?”
Answering my Own Question
I joined Datafold because I enjoy and respect Gleb, and Kira worked there too! And after talking with Leo and Graham, I knew it was going to be a splendid time and it was! I loved working there. I got the delight of contributing to data-diff, specifically the dbt integration to make it dead simple to diff data fast and give information you care about (looking at you Mike!). No more no less.

I closed the biggest deal in the company’s history and saw how my sales muscles didn’t stay confined to one context. I proved I could take these muscles anywhere with some cold, hard, juicy data: deals won. So now you’re thinking, “Sung, you silly man, why are you leaving for a dbt competitor?”
Because…of you, my data people, and how open source helps me connect with you.
The tools these companies make only win, only feel powerful, only have that charm when they treat you as the main character. I’m not even talking about, “customer is always right”. I’m talking, “I like and respect you as a person, as someone to solve problems side by side with: together. This only works when both of us win.” And that’s why I joined Tobiko Data, I’ve looked at their community slack for months and I’ve seen overwhelming evidence that they care. They’re not high and mighty big tech engineers coming to slam your heads with doctrinal stone tablets nor grovel at your feet with “pick me” energy. They treat you like adults. They treat you like peers. They’ll help you but they won’t do all your homework for you. And I’ve never felt more at home.

I care about you and how you work, and we need to have tough but fair conversations.
Design Foundations
I’m going to slap you with the cold, wet truth.
A lot of data tools, including dbt, cost a lot of money. I’m not even talking about licenses or usage based pricing. I’m talking your data warehouse. You’re probably not happy with your bill, so here’s a pro tip. Change your warehouse time to suspend idle to 1 minute vs. the default 10. You’ll probably save $500k after. You’re welcome.
On a more granular note, I’ve been quite shocked at the hundreds, and I mean hundreds, of dbt projects I’ve personally seen and helped improve or simply shrugged my shoulders and said, “Good luck”.
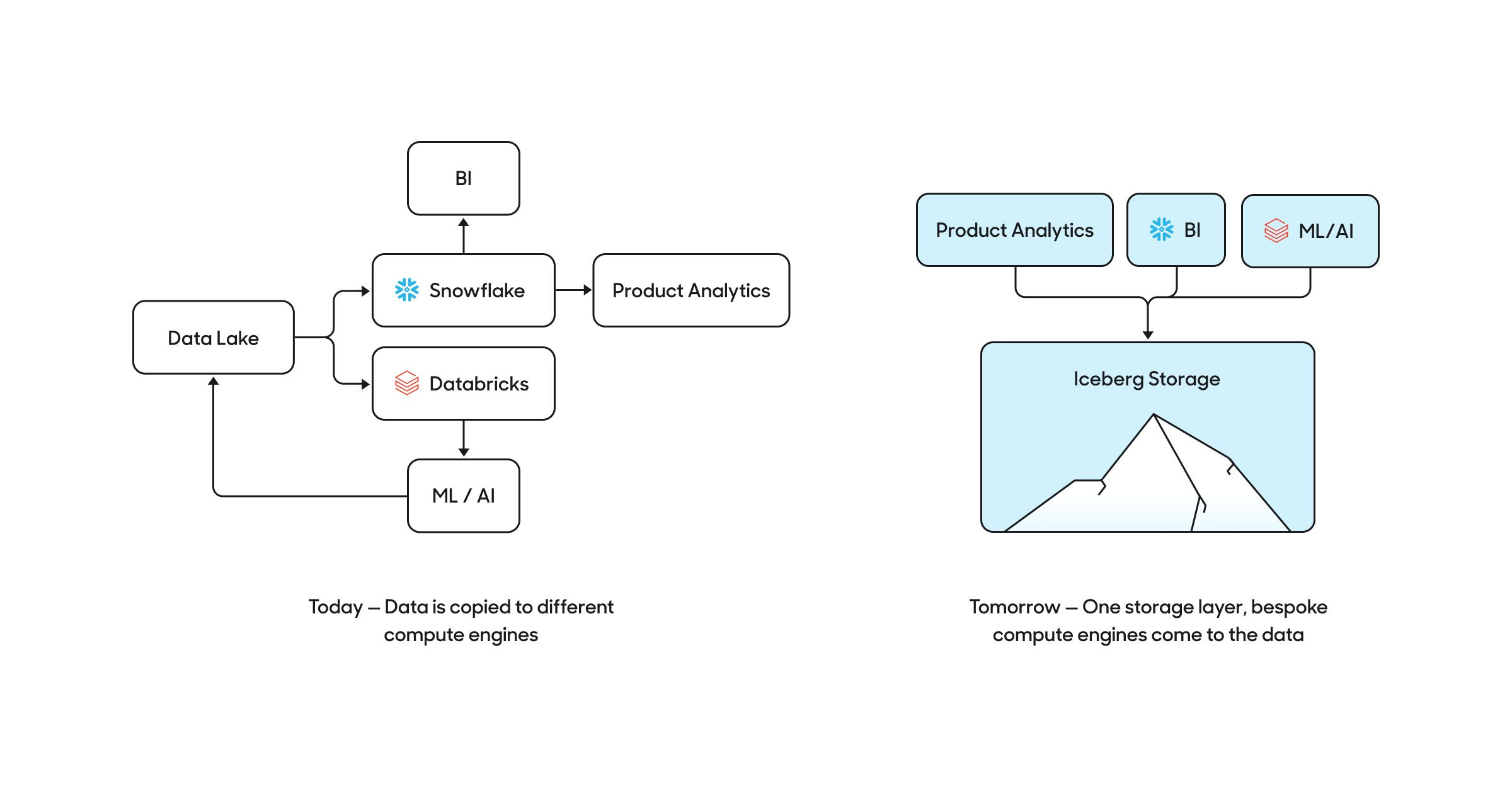
Let’s get specific: I’ve seen firsthand that Slim CI, defer to production, and scheduled mechanics of dbt don’t scale. They literally were never meant to. It’s a great tool to start for any small data team, but once you scale things break down. It’s NOT because analytics engineers are bad at their jobs. It’s because dbt was never designed for the battles that we need to face now: terabyte sized tables are becoming more normal, projects are growing in model count exponentially, and testing is too expensive to run against the warehouse. I’m not talking curated benchmarks. I’m talking real, living, breathing stories I’ve heard and seen side by side with people firsthand. I have seen several large dbt projects (think: 200+ dbt models) just stop using Slim CI because it takes too long, is brittle, and doesn’t actually catch the problems they want. Some have never even heard the term. Some have only run dbt run --select state:modified because adding the ‘+’ sign was too expensive and added too much noise (think: running 100 downstream models from simply adding 1 column-a non-breaking change). I’ve seen people just straight up not test their dbt models because they hate yaml bloat. I know this because I literally sold Datafold very successfully to finish the promise of Slim CI (making sure you don’t play guessing games before merging to prod). Heck, I’ve built a full, batteries-included, TODO comments weaved in everywhere tutorial.
This isn’t because the people at dbt Labs are these meanies (they’re actually wonderful-see above) with twisted incentives to keep database vendors happy with high warehouse utilization. It’s because the foundational design pattern of dbt is stateless and always will be.

dbt has no understanding of your actual data. It is an amazing SQL automation tool. It deserves all the flowers for playing this game well. I’m proud of the problems I’ve solved using dbt. Nothing can take that away from dbt Labs, me, and especially you. But I’ve seen talking with advanced dbt power users along with big tech data engineers, that they can’t afford to use tools that don’t understand data state as a first class citizen. I’ve seen them create their own forks of dbt or use Dagster or contort their workflows with a mess of jinja macros.
Imagine you thought you were playing with legos and wanted to switch out a piece here or there only to realize you’ve been playing with Jenga blocks the whole time. Yes, you can move fast, but things will break you. Jenga has its place, but it’s hard to scale that game with hundreds of people. I promise to write in greater detail about this in a future post.
Open Standards: A canonical SQL broker + State as a first class citizen
“What’s in the box? Pain”
In the months I’ve studied SQLGlot, SQLMesh, and most importantly, you as the open data community (I literally look at slack and reddit daily), it’s clear to me areas that deeply pain you (still).
Data pipeline pull requests are still guessing games and you are getting fed up with it.
You want to treat your data as infrastructure (not something to be torn down and rebuilt as a default) at the slightest syntax change.
You want to sell data but you don’t feel equipped
These things deserve the spotlight because I know I invoked memories of how painful AND important these areas can be. Don’t worry, Krazam is here to soothe you.
These problems need new foundations. We have been poking around in the dark with strings of text and calling it SQL. Writing words without knowing what they mean is a fools’ game. We should think the same of how tools run SQL.
SQLGlot Understands
I’m bullish that a deep, molecular, semantic understanding of SQL can serve as that foundation for all data work. Not as strings to be sent to a query engine, but as expressions. A known lexicon that a where clause is interpreted as a row-level filter, a hashing function to create surrogate primary keys is more than a function hard coded for a specific query engine. Something that makes column level lineage so easy to implement, it turns into a delightful commodity. Oh wait, dbt Cloud’s AND Dagster’s column level lineage are powered by SQLGlot. Here’s a video of me showing you quick and dirty highlights.
And you know what’s nice. I just killed two birds with one stone. All that development work you saw right there: free. All running on my local machine. And that’s right, a unit tested macro in python using SQLGlot. I’ve literally never seen any dbt project (that isn’t a dbt package) unit test their jinja macros directly, including me. And I contributed to dbt open source heavily. So deduce what you will from that.
SQLMesh is Stateful
And oh I lied. I killed 3 birds with one stone. I merged in a non breaking change into my prod environment without having to recreate a bunch of downstream SQL models. Slim CI isn’t a concept you have to learn, much less know, it’s the default experience. And when it’s the default, you get to focus on more important things.
And when state is a first class experience, it’s hard to go back. Don’t get me wrong. It took me a week to really FEEL how it works before it became muscle memory. And let me tell you, my muscles feel plump and juicy🧃, just how I like them. And there’s a lot more to learn. I’m not a pro yet, but I have every motivation because how else will I connect with you, my data people.
With their Powers Combined
I’m excited for a new world to be true: transforming data is intuitive for data analysts and powerful for data engineers. I want to live in a world where the most expensive thing is how much time we spend thinking about solving a problem, not babysitting query costs or long running queries. I want to live in a world where running queries is like programmatic bidding. Where query engines must prove to us they are best in class (price/performance) everyday, nay, every second, for us to run queries on them because the same SQL expressions can literally run on any query engine because of SQLGlot, because of SQLMesh (sprinkle in Iceberg too), because state as a first class, open, standard matters. Because most importantly, we deserve way way better.
What Now?
We exist to find each other.
You’re going to see a flurry of content I’ve been slow cooking in the oven for months now. All this juice is hand crafted. No LLMs to ghost write for me. No AI video generation to replace my demo videos. I’m not here to push content to hyper optimize for the ranking algorithms. I’m doing it to find you, my data people, and I know I’ll find you when we serendipitously reach out to each other in Tobiko’s slack or DMs and chat about the work we love and the things in work and life that should suck less.
Open source has my whole heart because it’s how I found you:
People I love working with all the time.
Talk with me! I’m pretty extroverted. When you reach out to me, I am filled with joy and will reply with earnestness:
If you’re in Los Angeles, let’s meet up :). Some suggestions that have been battle-tested by my taste buds. The meal’s on me 🧃.
Tsujita Annex (great ramen)
Brothers Cousins (best al pastor burritos)
Father’s Office (best burger)
Here Fishy Fishy (best all you can eat sushi)
You’re so cool Sung